前回はMySQLのオプティマイザの挙動について詳しく学びましたが、今回はオプティマイザが動作するにあたって必要な情報について確認していきます。
MySQL 5.7から新たに、server_cost、engine_costというスキーマが導入されてオプティマイザがクエリの実行計画をコスト計算をもとに作成するような仕組みになっています。
今回は、MySQL8の内容にも触れながら学んでいきます。
MySQL8の内容についてはとくに下記の書籍が参考になりますので、ぜひ、手に取ってみてください。
1. コスト算出方法
MySQLのオプティマイザはコストモデルというのを利用して、実行計画を作成します。
実行計画とは、受け取ったSQLを最適化するプロセスのことです。綿密なコスト計算に基づいた複数のプランを算出し、その中から一番コストが低いものが最適化案として採用されます。
見積もり算出のために、server_cost、engine_costというテーブルが用意されています。5.7ではデフォルト値はオンコーディングで実装されていますが、8.1では、カスタマイズ可能なテーブルとして用意されています。
エンジンコスト(engine_cost)
エンジンコストのパラメータは2種類のみで、ディスクから読みとる場合とメモリから読み取る場合になります。
現在、スペースリーでは、Amazon Auroraを利用していますが、そちらの環境での最適化などを提案している文献が見つからないので、深くは追求しません。
| engine_name | device_type | cost_name | cost_value | 初期値 | 意味 |
|---|---|---|---|---|---|
| default | 0 | io_block_read_cost | NULL | 40.0 | ディスクから読み取る場合のコスト |
| default | 0 | memory_block_read_cost | NULL | 2.0 | メモリから読み取る場合のコスト |
サーバーコスト(server_cost)
こちらのコストはクエリ実行計画の作成に大きなインパクトを与えます。
行数と掛け合わせて最終的なコストの見積もりをするためです。
| cost_name | cost_value | 初期値 | 意味 |
|---|---|---|---|
| disk_temptable_create_cost | NULL | 20 | (MyIsamやInnoDBの内部的な)のテンポラリテーブルの作成コスト ディスクへの書き込みが発生する |
| disk_temptable_row_cost | NULL | 0.5 | 上記の行単位コスト |
| key_compare_cost | 0.1 | 0.05 | レコードキーを比較するコスト この値を増やすと、多数のキーを比較するクエリー計画のコストが高くなり、インデックスソート < ファイルソートとなりえる |
| memory_temptable_create_cost | NULL | 1.0 | インメモリのテンポラリテーブルの作成コスト disk_temptable_row_costよりもコストが低いため、オプティマイザが選択しがち |
| memory_temptable_row_cost | NULL | 0.1 | 上記の行単位コスト |
| row_evaluate_cost | NULL | 0.1 | 行を評価するための一般的なコスト この値を増やすと、多数の行を調査するクエリー計画が、調査する行数が少ないクエリー計画よりもコストが高くなり、 少量のレンジスキャン< テーブルスキャンとなりえる |
- 複数のテーブルを結合してSELECTする複雑なクエリの場合には、各テーブルへのアクセスコストのみならず、結合順序と利用されるインデックスも考慮する必要があります
OUTER STRAIGHT JOINの場合には、結合順序は固定ですが、INNER JOINの場合にはオプティマイザがコストを元に選択します- テーブルの組み合わせは、
N!(Nの階乗)となることに注意が必要です- 5つのテーブルを結合する場合の組み合わせは、5 * 4* 3* 2 * 1 =
120通り
- 5つのテーブルを結合する場合の組み合わせは、5 * 4* 3* 2 * 1 =
- MySQLは61テーブルまでJOINすることが可能ですが、 検討するプランの組み合わせが多くなり過ぎた場合に、見積もりの時間がかかりすぎる事があるので、注意が必要です
optimizer_prune_levelやoptimizer_search_depthで刈り込みの設定をすることができます
2. インデックスダイブと統計情報
MySQLにはインデックスダイブという機能があり、range (範囲)スキャンの場合に、オプティマイザーがその範囲に含まれる行数を正確に見積もるための仕組みです。
eq_range_index_dive_limitという変数に閾値が格納されていて、その範囲内であれば、インデックスダイブを利用、範囲外であればインデックス統計を利用するという仕組みなっています。
オプティマイザがコストを算出するために行数を数えるときに必要になります。
- rangeスキャンとは、INやOR句にIDを直接指定したり、不等号記号(<,>=....)やBETWEENなどの句で指定された場合の最適化のこと
- インデックスダイブを利用するということは、 handler::records_in_rangeを利用するかどうかということと同じ意味です
3. 統計情報
統計情報は、mysql.innodb_table_stats、mysql.innodb_index_statsというテーブルに格納されています。
テーブルごとの統計情報

インデックスごとの統計情報

デフォルトでは、innodb_stats_auto_recalc というパラメーターがONになっており、テーブル全体の10%の以上の行が更新されたら更新されます。
頻繁に統計が再計算される可能性があり、これにより、クエリーの実行計画が変化する可能性があります。
ローカルでクエリの実行計画をデバックする際には、常に最新化されている事を意識したいところです。
Analyze Tableコマンドの実行で即時に更新することができます。
その場合には、頻繁に統計情報を再計算することでサーバーへの負荷が高くなるので注意が必要です。
innodb_stats_persistentを利用することで再起動しても統計情報は消えなくなります。
MySQL :: MySQL 8.0 リファレンスマニュアル :: 15.8.10.1 永続的オプティマイザ統計のパラメータの構成
また、テーブルごとに永続化をする方法もあります。
その場合、書き込み時に負荷がかかるので必要なテーブルに限定することをおすすめします。
STATS_PERSISTENTのパラメーター一覧
| キー | 初期値 | 意味 |
|---|---|---|
| STATS_PERSISTENT | 1 | 永続化を有効 |
| STATS_SAMPLE_PAGES | 20 | サンプリングされるページのデフォルト数を20に設定 |
| STATS_AUTO_RECALC | 11 | テーブルに対する大幅な変更後に統計を自動的に更新するかどうかを制御 |
- STATS_SAMPLE_PAGESで指定するページ数とは、Bツリーインデックス のリーフの数です
- SQLアンチパターンとBtreeインデックスの関連性の説明が分かりやすいのでこちらをご覧ください
- 下記の事象が発生したときのみ、
STATS_SAMPLE_PAGESのチューニングが必要になりますANALYZE TABLEが遅すぎる- 統計の精度が十分でないため、オプティマイザが次善の計画を選択する
show indexes from TABLE_NAME;で表示されるインデックスごとの実際のカーディナリティを比較して確認をします。stat_nameがn_diff_pfx${NN}の場合のstat_valueがカーディナリティを示します。
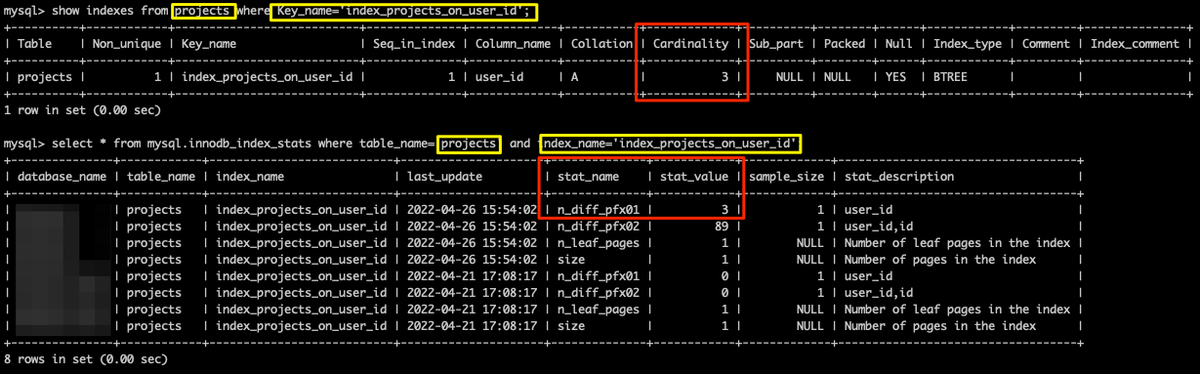
- また、少々蛇足ではありますが、InnoDBではしばしフラグメンテーションが発生する場合があるので、Optimize Tableを実行することで、インデックスデータの物理ストレージを再編成して、性能を向上できます
4. hash_joinとヒストグラム
前回の学習でも触れましたが、MySQL8では、オプティマイザに新たに、hash_joinがという機能が導入されました。
hash_joinはインデックスがない場合に、hash_keyを作成してそれをもとに結合を行います。
その際に、オプティマイザ統計情報として利用するヒストグラムも新たに導入されました。
ここでいうヒストグラムとは言わずとしれたヒストグラムの事で、階級ごとに度数を保持する統計情報です。
hash_join結合において、indexと似たような働きをします。- joinの結合順序を最適化するのに利用されます。
- 上述の、
mysql.innodb_table_statsと同様にAnalyze Tableの実行で最新化する事ができます。 optimizer_switch変数のcondition_fanout_filterをOFFにすることで無効化することもできます。