はじめに
スペースリーでインターンをしている大隣嵩です。
1枚の画像から家具の3D形状復元を行う問題は、結果が1つに定まらない不良設定問題です。しかし、深層学習を用いて、カテゴリ特有の形状に関する事前知識を獲得し、精度向上を達成した手法がいくつか提案されています。
ShaRF[1]では、1枚のオブジェクトを撮影した画像からカテゴリ固有の3D形状復元を行う手法が提案されました。ShaRFの目標は、NeRF[2]を用いて、1枚の画像からの任意視点画像合成を高精度に行うことですが、そのために、中間表現として、オブジェクトの3D形状復元を行います。まずは、ShaRFを理解する上で必要となる任意視点画像合成とNeRFの説明をします。その後、ShaRFの概要と行った実験の紹介をします。
また、本記事ではShapeNet[3]を用いた実験を紹介しますが、再現実験のための研究用途での使用で、実際のアプリケーションでは自前で用意したデータセットを学習用データセットとして使用します。
NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis
複数視点の画像から、シーンの未知の視点の画像を合成するタスクは任意視点画像合成(Novel View Synthesis)と呼ばれます。VRやAR、スポーツで任意視点からの映像作成をサポートする技術です。任意視点画像合成を実現するためには、画像群から3次元表現を推定する必要があり、様々な3次元表現を用いた手法が提案されています。近年、3次元表現をニューラルネットワークにより連続的に表現する手法が点群・メッシュ・ボクセルなどの離散的な表現よりも高解像度を実現できることから注目されています。その中でも、2020年に提案されたNeRF[2]は、従来手法と比べて大幅に高精度な任意視点画像合成を達成し、多くの関連した研究がなされています。
NeRFでは、高精度な任意視点画像合成を実現するために、3次元上の点における位置・方向から色・密度で構成される輝度場表現を学習します。ここでは、NeRFの画像合成・学習の流れについて図1に沿って簡単に説明します。

まず(a)で、カメラ中心 $\boldsymbol{o}$から2次元画像上のピクセルに向かって光線 $\boldsymbol{r}(t)=\boldsymbol{o}+t\boldsymbol{d}$を照射し、3次元空間上の位置 $p\in\mathbb{R}^3$と視線方向 $d\in\mathbb{R}^2$の5次元データを取得します。次に(b)で、この5次元データをMLPに入力し、色 $\boldsymbol{c}$と密度 の出力を得ます。続いて(c)では、ボリュームレンダリング方程式により光線に沿った色と密度から2次元画像上のピクセルの色$\boldsymbol{\hat{C}}(\boldsymbol{r})$の計算を行います。
\begin{equation} \begin{split} \boldsymbol{\hat{C}}(\boldsymbol{r}) &= \sum_{i=1}^N T_i(1-\exp(-σ_i\delta_i))\boldsymbol{c}_i,\\ & \mathrm{where}\ T_i = \exp\left(-\sum_{j=1}^{i-1}σ_j\delta_j\right) \end{split} \end{equation}
最後に(d)で、合成した色$\boldsymbol{\hat{C}}(\boldsymbol{r})$と正解の色の2乗誤差を損失関数として計算し、NeRFの学習を行います。他にも、学習戦略として、coarse-to-fineな2段階サンプリングや位置・方向の埋め込みなどを採用しています。詳細は元論文を参照してください。
ShaRFのAppearance networkでは、追加の入力として、Appearance code $\phi$や占有率 $\alpha_p$がありますが、それ以外の色の計算や、学習の方法などはNeRFと同じです。
ShaRF: Shape-conditioned Radiance Fields from a Single View
概要
ShaRF[1]の目標は1枚の画像からNeRF[2]で提案された輝度場を学習し、高精度な任意視点画像合成を実現することです。この目標を達成するために、オブジェクトの形状に関するShape codeと外観に関するAppearance codeという2つの潜在変数でシーンを条件付けし、中間表現として、対象とするオブジェクトのボクセル表現の推定も行います。こうすることで、オブジェクトの形状と外観を明示的に表現し、Appearance networkがより正確な表現を出力するよう誘導できます。また、ShaRFでは推論時にも最適化を行うため、学習データセットと異なるドメインのデータに適用するのに効果的です。以上をまとめると、ShaRFの貢献は以下の3つです。
- 1枚の画像からオブジェクトを復元するための新たなモデルを提案
- 1枚の画像から高精度な任意視点画像合成を実現するために、ボクセルによる中間表現で輝度場を条件付けする新たな表現の提案
- 学習時との分布が異なる実画像からの輝度場の推定をするための最適化、ファインチューニングの提案

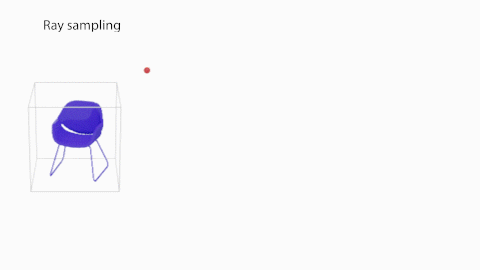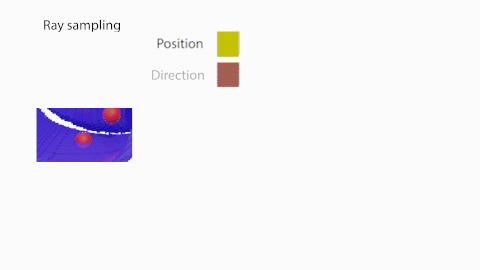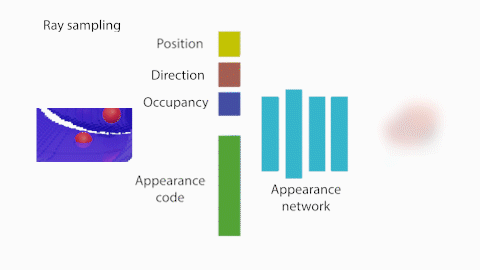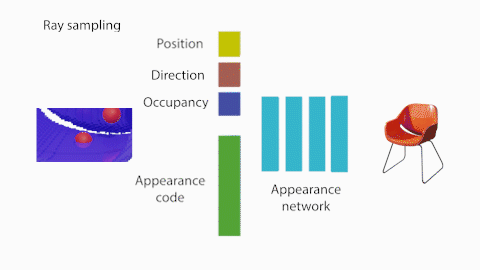
図2に示したShaRFの処理の概要について説明します。まず、Shape network $G$はShape code $\theta$を、占有率を保持する$V\in{\mathbb{R}^{128}}^3$のボクセル空間にマッピングします。シーンのオブジェクトが存在する領域を指定し、その領域についてオブジェクトの占有率を推論します。
次に、NeRFの輝度場を拡張したAppearance network $F$を用いて、シーンの任意の位置 $\boldsymbol{p}$・方向 $\boldsymbol{d}$における色 $\boldsymbol{c}$・密度 を出力します。
\begin{equation} \begin{split} F(\boldsymbol{p}, \boldsymbol{d}, \alpha_p, \phi) &\Rightarrow \boldsymbol{c}, σ \end{split} \end{equation}
NeRFと比較して2つの入力が新たに加わっています: (1) 点$p$におけるShape networkが生成するボクセル表現$V$の占有率$\alpha_p$、(2) 外観を表現するAppearance code $\phi$。
Appearance networkから出力される色と密度から、NeRFと同じボリュームレンダリングの足し合わせで、各ピクセルの色が合成されます。Shape codeから色が合成されるまでの流れは全て微分可能であるため、合成された色と正解の色を近づけるように学習されます。
続いて、各ネットワークの構成、学習・推論の処理について説明します。
Shape Network
Shape Networkは、先述の通り、Shape code $\theta$を、占有率を保持する$V\in{\mathbb{R}^{128}}^3$のボクセル空間にマッピングします。Shape Networkは一般的な全結合層と3次元畳み込みブロックで構成されます。このボクセル表現から3次元空間上の点$p$における占有率$\alpha_p$をトリリニア補間により求めて、Appearance Networkの追加の入力としています。
学習データとして特定のカテゴリ(論文内では椅子や車)を使用し、各オブジェクトはそれぞれ形状を表現する潜在変数(Shape code)$\theta$を持ちます。学習時は、Shape network $G$と、潜在変数 $\theta$の両方の最適化を行います。損失関数は以下の要素から構成されます。
(1) 予測した占有率 $\hat{\alpha}$ と正解の占有率 $\alpha$ での重み付きのバイナリクロスエントロピー
(2) オブジェクトが左右対称であると仮定したボクセルの対称性損失
(3) ボクセルからシルエット画像を合成した時の、正解画像とのシルエット損失。
\begin{equation} \begin{split} \frac{1}{|V|}&\sum_{i\in V}{\gamma\alpha_i\log{\hat{\alpha_i}}+(1-\gamma)(1-\alpha_i)\log{(1-\hat{\alpha_i})}} \\ &+w_{sym}||\hat{V}-\hat{V}_{sym}||^2 +w_{proj}\sum_{j\in{1, 2}}||\mathcal{P}_j(\hat{V})-S_j||^2 \end{split} \end{equation}
ここで、$w_{sym}$(論文では0.9)、$w_{proj}$(論文では0.01)はそれぞれ対称性損失とシルエット損失の重み、$\gamma$(論文では0.8)は占有領域に対する重み、$\mathcal{P}_j$はボクセルからシルエット画像への微分可能な投影演算子です。
以上の、損失関数からわかるように、ShaRFでは、学習のためにボクセルなどのNeRFでは要求されなかった追加の入力が必要になります。NeRFで要求される内外のカメラパラメータに加えて、ShaRFで学習時に必要となる入力は大きく分けて3つあります。
- シルエット画像
- ボクセル
- ボクセルの位置・方向
以上の入力は、現存するShapeNetやPix3Dのデータからは正確な値がアノテーションされており、利用することができますが、自前のデータセットでこれらの正確なデータを用意するのは難しく、実際のアプリケーションにShaRFを適用する際の障壁となります。
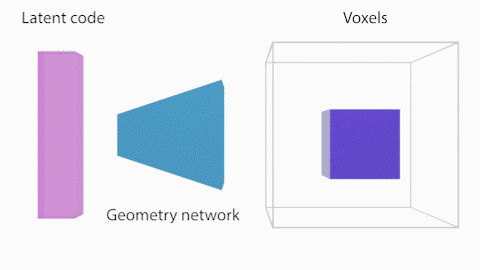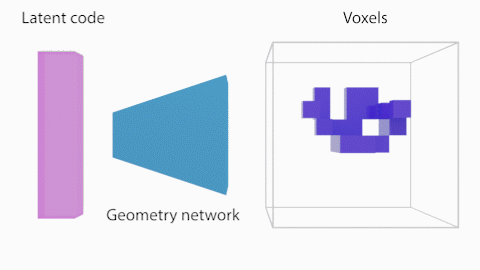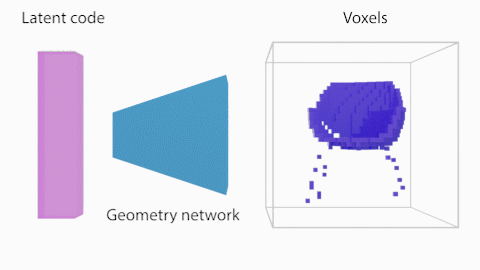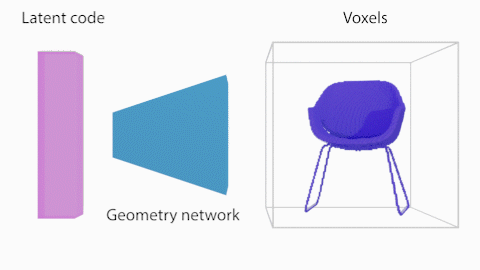
Appearance Network
Appearance Networkは、先述の通り、点$p$におけるShape networkが生成するボクセル表現$V$の占有率$\alpha_p$と、外観を表現するAppearance code $\phi$を追加の入力として、輝度場を学習します。NeRFと同様に、全結合層で構成されます。
学習データとして、Shape Networkと同様、特定のカテゴリ(論文内では椅子や車)を使用し、各オブジェクトは、外観を表現する潜在変数(Appearance code)$\phi$を持ちます。各オブジェクトで50枚の画像を用意し、各画像に対して、正しい画像が合成されるようにAppearance codeとAppearance Networkを学習します。追加入力として与える占有率$\alpha_p$は、Shape networkの出力をそのまま用いることができますが、まず、正解データを用いてAppearance Networkを事前学習し、その後、Shape networkの出力を用いてファインチューニングを行うことにより、より高精度な画像合成ができるそうです。
推論時の処理
テスト画像での潜在変数($\theta, \phi$)は学習時のデータを使って推定する必要があります。そのため、ShaRFでは推論時にも最適化を行い、推論データに適した潜在変数、ネットワークを求めます。潜在変数とネットワークの推論時最適化により、テスト画像が学習データセットと異なるドメインであっても、より詳細な形状復元と画像合成ができることが確認されています。つまり、この推論時最適化によって、潜在変数やネットワークを特定のテスト画像に過適合させていると言えます。しかし、この推論時最適化により、学習時と同様に、シルエット画像や、ボクセルの位置・方向などの追加の入力が必要となります。これは、ShaRFの推論を実際のシーンで行う際の障壁となります。 推論時の処理は2ステップで行われます。
1. Shape code $\theta$ と Shape network $G$ の最適化
テスト画像内の物体の正確な形状(ボクセル)推定を行うために、物体の形状を制御する潜在変数(Shape code)とShape Networkのパラメータを最適化します。HOG画像特徴量により、テスト画像と最も類似する学習画像を求めて、その学習画像の潜在変数を初期値とします。また、ボクセルの対称性損失とボクセルのシルエット損失を損失関数とします。


2. Appearance code $\phi$ と Appearance network $F$ の最適化
次に、物体の形状を表現する潜在変数(Shape code)とShape networkのパラメータを固定し、物体の外観を制御する潜在変数(Appearance code)とAppearance networkのパラメータを最適化します。学習時と同様に、生成画像の再構成損失を損失関数とします。
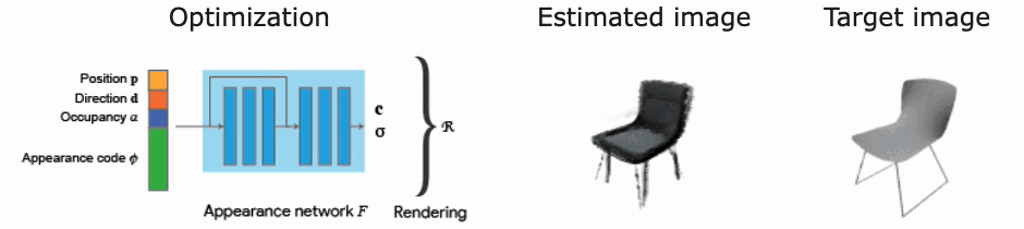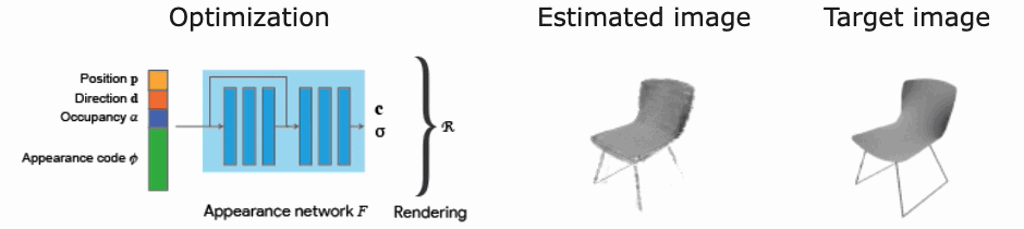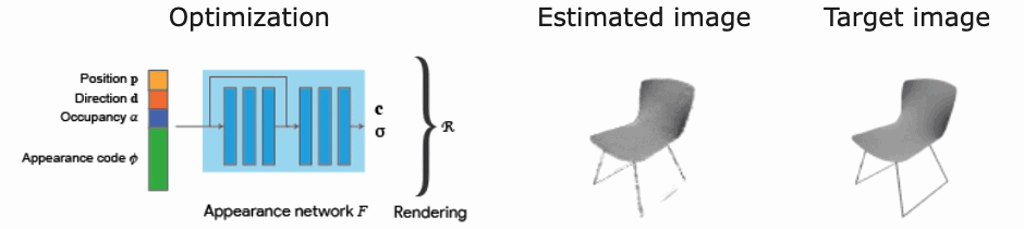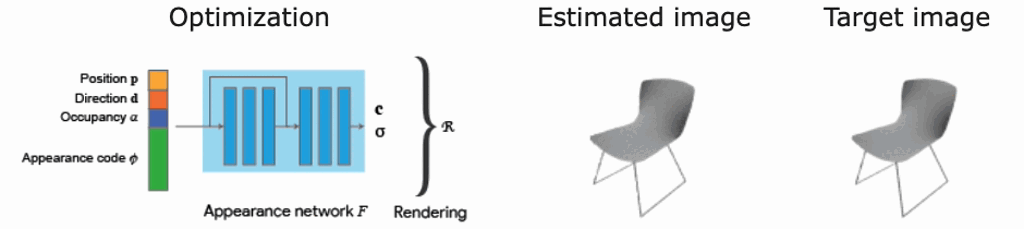

論文内の実験概略
ここでは、私たち実サービスを見据えて関心のある部分に絞って、ShaRFで行われた実験について説明します。具体的には、実シーンへの利用可能性と、ボクセル表現の復元精度になります。
Pix3Dでの評価
ShapeNet[3]で学習したShaRFモデルをPix3D[4]に適用し、異なるドメインへの汎化性能を実験しています。図9のように、ShapeNetを使って学習したモデルで、Pix3Dデータの推論がうまくいっていることがわかります。この結果は、ShaRFの異なるドメインへの適用可能性を示唆しています。

形状復元の評価
ShaRFは、椅子に対してOccupancy Networks[5]と同等の精度(ShaRF 0.49 vs [5] 0.50 IoU)、車に対してより良い精度(ShaRF 0.77 vs [5] 0.74 IoU)となっています。しかし、ShaRFはクラス固有のモデルなのでこの比較は近似的なものです。また、ShaRFはあくまでも、正確な任意視点画像合成のために3D形状復元を利用しているだけなので、形状復元の精度はShaRFの論文では関心外であることに注意が必要です。
実験結果
実験条件
テクスチャのない3D形状復元を行うため、輝度場は使わずに、Shape codeとShape networkを用いた実験を行いました。tensorflow-graphicsの実装を元に、学習と推論の流れを構築しました。学習データセットとしてShapeNet[3]とPix3D[4]、推論データセットとしてPix3Dを使用しました。ShapeNetは商用利用ができないライセンスになってるので、再現実験のみに利用し、実際のアプリケーションでは自前のデータセットを使用します。自前のデータセットで大量のカメラパラメータ、3Dモデル付きデータセットを用意するのは困難なため、条件を緩めて、カメラパラメータのない3Dモデルを学習モデルとして想定しました。そのため、学習時には、シルエット損失を使用せず、ボクセルのクロスエントロピー損失と対称性損失を使いました。また、自前のデータセットで大量の学習データを用意するのは難しく、そもそも学習に効果があるのかを確認するため、(1) ShapeNetの全データを用いた学習(大量データで学習)、(2) ShapeNetあるいはPix3Dのうち限られた量(100個)のデータを用いた学習(少量データで学習)、(3) 事前学習なしの3つの学習状況を再現しました。ロスの重みなどのハイパーパラメータはShaRFの論文やプロジェクトページに記載されている値を参考にしました。
定量的な結果
chair、bed、sofa、table、deskの5カテゴリについて各カテゴリ100個のテストデータをPix3Dから用意し、推論されるボクセルと正解のボクセルによるIoUが閾値を超えるデータ数を可視化しました(図10)。IoUが高い時に閾値を超えるデータが多い方が良いので、グラフが右上にある方がいい結果になります。結果より、bed以外では事前学習の効果が見られました。ベッドでは、ベッドの頭の部分にあたるヘッドボードが複雑なものが多く、データを増やしても学習の効果が生じにくかったと考えています。また、事前学習を行う場合は、少量データでも大量のデータを使う場合とは大きく変わらない結果になっているのが興味深いです。
 |  |
 |  |
 |
図10: 定量的な結果。曲線が右上にあるほどいい結果となる。
定性的な結果
推論結果であるボクセル表現をマーチングキューブ法でメッシュ化し、定性的な評価を行いました。各カテゴリの結果を以下に示します。定性的にも、事前学習をすることで正解に近いメッシュが生成できていることがわかります。
表1: 定性的な結果。
| カテゴリ | Ground Truth | 事前学習なし | 少量データでの学習 | 大量データでの学習 |
|---|---|---|---|---|
| chair |  |
 |
 |
 |
| bed | 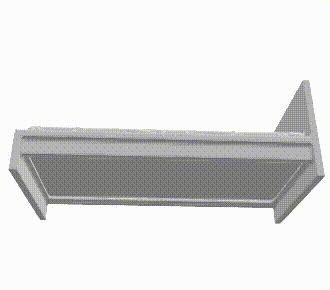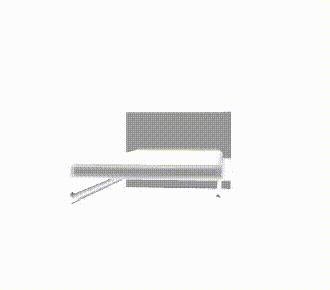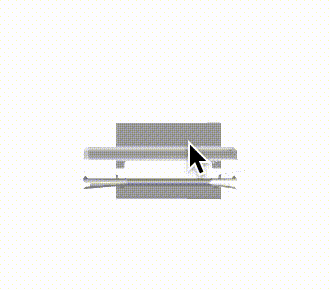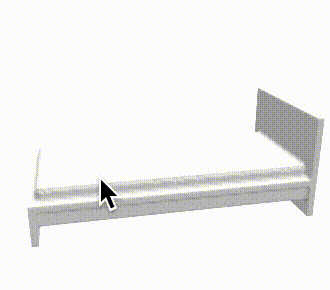 |
 |
 |
 |
| sofa | 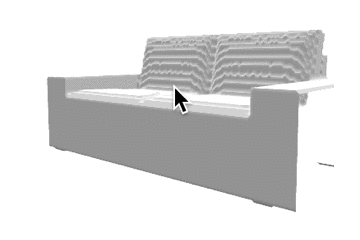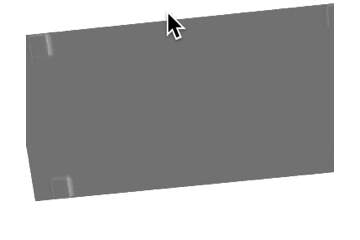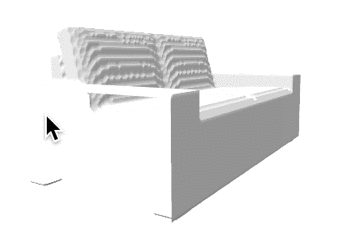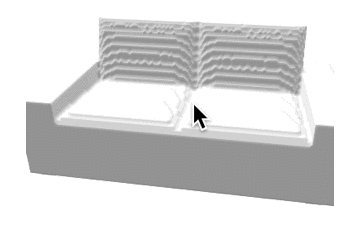 |
 |
 |
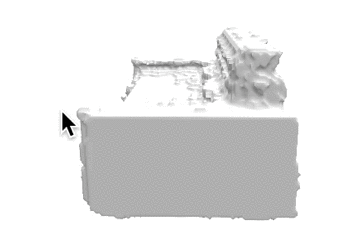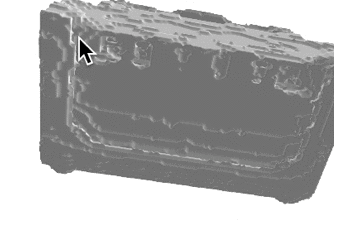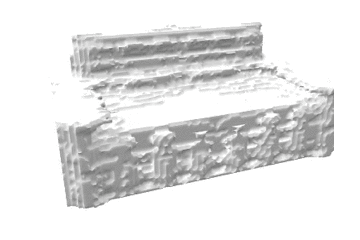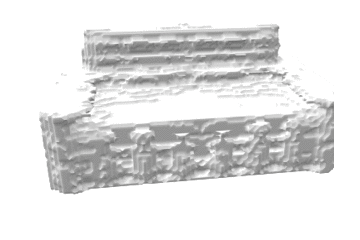 |
| table | 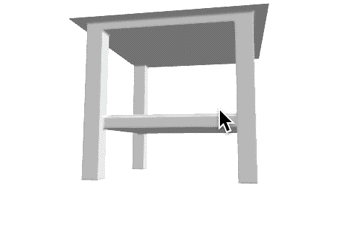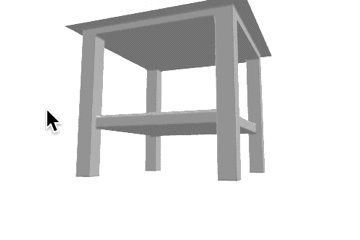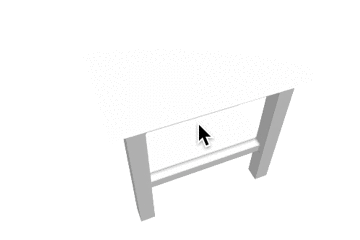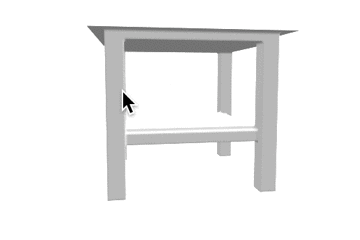 |
 |
 |
 |
| desk | 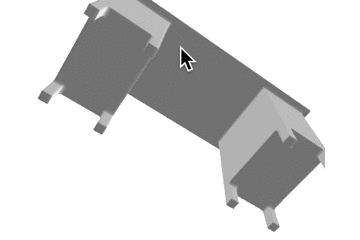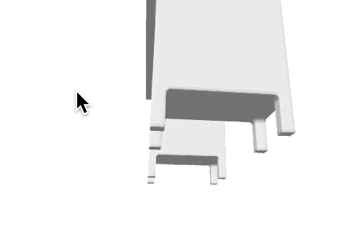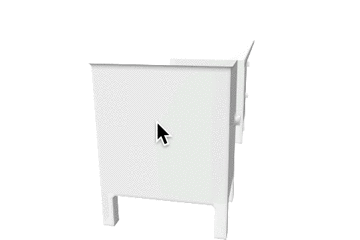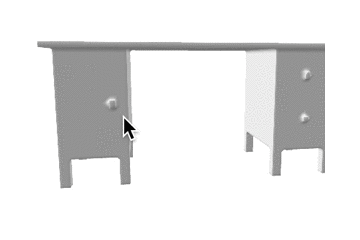 |
 |
 |
 |
まとめ
1枚の画像から高精度なオブジェクト3D復元を可能としたShaRFの概要と実験した結果を紹介しました。従来の単眼オブジェクト3D復元の手法だと、学習データセットに過適合を起こし、分布外のデータにうまく汎化できませんでした。ShaRFでは、推論時に最適化を行い、入力したシルエットに合ったボクセルを生成することから、この問題は起きにくいと考えられます。また、ボクセルを生成するまでの処理はShape codeとShape networkのみを使用し、ネットワークが単純なのも特徴的です。今後は、Appearance networkを使用したテクスチャありの3Dモデル生成や、実際のデータを使った実験を行うことを考えています。
参考文献
[1] Konstantinos Rematas, Ricardo Martin-Brualla and Vittorio Ferrari. Sharf: Shape-conditioned Radiance Fields from a Single View. In ICML, 2021.
[2] Ben Mildenhall, Pratul P. Srinivasan, Matthew Tancik, Jonathan T. Barron, Ravi Ramamoorthi and Ren Ng. NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis. In ECCV, 2020.
[3] Angel X. Chang, Thomas Funkhouser, Leonidas Guibas, Pat Hanrahan, Qixing Huang, Zimo Li, Silvio Savarese, Manolis Savva, Shuran Song, Hao Su, Jianxiong Xiao, Li Yi, and Fisher Yu. ShapeNet: An Information-Rich 3D Model Repository. arXiv:1512.03012, 2015.
[4] Xingyuan Sun, Jiajun Wu, Xiuming Zhang, Zhoutong Zhang, Chengkai Zhang, Tianfan Xue, Joshua B. Tenenbaum and William T. Freeman. Pix3D: Dataset and Methods for Single-Image 3D Shape Modeling. In CVPR, 2018.
[5] Lars Mescheder, Michael Oechsle, Michael Niemeyer, Sebastian Nowozin and Andreas Geiger. Occupancy Networks: Learning 3D Reconstruction in Function Space. In CVPR, 2019.