いよいよ、昨年11月から、Amazon Aurora 8.0がリリースされ、8.0への移行の日が差し迫ってきました。
Spacelyでは、現在、Aurora MySQL5.7を利用していますが、8.0移行の前準備として、最近の最適化の仕組みを学びはじめました。
筆者が知っている時代よりも、最適化プロセス(オプティマイザの機能)がかなり高機能なものになっており、今まで思い込んでいた、勝手に作られるTemporary Tableが遅いとか、サブクエリが遅いとか、INよりEXISTSが早いとか・・・・・そういった固定観念を一気に拭うときがやってきたようです。インデックスが貼られていないと遅すぎてサーバーがマシンごとヒートアップする・・・というのも近い将来には見なくなる光景かもしれません・・・
今回は、Optimizer関連の変数を確認しながら最適化について学びます。
MySQL初心者や忘れてしまった方は以下のドキュメントや書籍を参考にするといいと思います。
1. オプティマイザ関連の変数について
※ 5.6(または8)の日本語ドキュメントを参照先として設定しています。
optimizer_prune_level、optimizer_search_depth 、optimizer_switch、range_optimizer_max_mem_size などオプティマイザ自身の動作に関するパラメーター、optimizer_traceから始まるオプティマイザの挙動をトレースするにあたって必要なパラメーターと2種類あります
| パラメータ | 初期値 | 解説 |
|---|---|---|
| optimizer_prune_level | 1 | 実行計画の見積もりの粒度 テーブルごとにアクセスされる行数の見積もり(経験則)に基づいて、見込みのないプランを一部刈り込む 0を指定すると経験則を無効にできる |
| optimizer_search_depth | 62 | 実行計画の検索深度 クエリー内のリレーションの数より値が大きいと、適切なクエリー計画が得られるが、実行計画の生成に時間がかかり、値が小さいと、実行プランがすばやく返される 後者の場合、結果のプランが最適にならないことがある 0を指定することで自動判別を行ってくれる 大きすぎると指数関数的に検証するプランが増えてしまうので注意が必要 |
| optimizer_switch |
index_merge=on, index_merge_union=on, .......省略........ |
(2. optimizer_switchの詳細を参照) |
| optimizer_trace | enabled=off, one_line=off |
実行計画のjsonトレース enabled=onの時にトレースが有効 |
| optimizer_trace_features | greedy_search=on, range_optimizer=on, dynamic_range=on, repeated_subselect=on |
トレースする機能を指定する |
| optimizer_trace_limit | 1 | 表示されるオプティマイザトレースの最大値 |
| optimizer_trace_max_mem_size | 16384 |
オプティマイザトレースの最大累積サイズ オプティマイザがトレースログ出力するのに必要なメモリのサイズ |
| optimizer_trace_offset | -1 | 表示されるオプティマイザトレースの最初のオフセット |
| range_optimizer_max_mem_size | 8388608 | 範囲オプティマイザで使用可能なメモリーを制御 0を指定することで無限になる |
range_optimizer_max_mem_sizeが適切でない場合に、オプティマイザが最適化候補の検索を諦めてフルスキャンする問題が報告されているので、こちらも気をつけましょうinnodb_buffer_pool_sizeへのメモリ割り当ての追加で、rangeスキャンの性能が向上します- DB単体のサーバーであればメモリの80%を利用できるともいわれている
- Auroraでは
{変数}インスタンスメモリの 3/4という設定になっているので最適化されていると思われます
2. optimizer_switchの詳細
optimizer_switchはスイッチON/OFFにより最適化をする/しないを設定できます。
| optimizer_switch | デフォルト値 | 意味 |
|---|---|---|
| index_merge | on |
インデックスマージ 複数の rangeスキャンによって、行を取得しそれらの結果を 1 つにマージする機能 ※ 単一のテーブルからのスキャン結果のみマージをする ※ rangeスキャンとは、INやOR句にIDを直接指定したり、不等号記号(<,>=....)やBETWEENなどの句で指定された場合の最適化のこと e.g. WHERE t1.key1 IN (1,2) OR t1.key2 = 20 OR t1.key3 < 30 |
| index_merge_union | on |
インデックスマージ WHERE 句が【OR】で組み合わされたさまざまなキーに対する複数の範囲条件の和集合 e.g. WHERE key1 = 1 OR key2 = 2 OR key3 = 3 |
| index_merge_sort_union | on |
インデックスマージ WHERE 句が【OR】で組み合わされた複数の範囲条件の和集合 ※ index_merge_unionを適用できない場合に採用 ※ index_merge_unionとの違いは行を返却する前にsortすること e.g. WHERE (key_col1 > 10 OR key_col2 = 20) |
| index_merge_intersection | on |
インデックスマージ WHERE 句が【AND】で結合されたさまざまなキーに対する複数の範囲条件の積集合 e.g. WHERE (key_col1 > 10 AND key_col2 = 20) |
| engine_condition_pushdown | on |
コンディションプッシュダウン インデックスが設定されていないカラムと定数(a=10 など)との直接比較の効率性を向上する ※ デフォルトで有効だが、NDBを利用していなければ関係ない e.g. WHERE (no_key > 10 AND key_col2 = 20) |
| index_condition_pushdown | on |
コンディションプッシュダウン インデックスを使用してテーブルから行を取得する場合の最適化 ※ デフォルトで有効だが、NDBを利用していなければ関係ない |
|
|
on |
Multi-Range Read ランダムディスクアクセスの回数を軽減する最適化 ※ MRR: ディスクの並び順に従ってデータファイルを読み取るアルゴリズムを利用 ※ index読み取り => 行番号でのソート=> ソート順での行の取得を行う |
| mrr_cost_based | on |
Multi-Range Read mrr=on の場合にコストベースの MRR の使用を制御 |
| block_nested_loop | on |
Block Nested Loop オプティマイザがどのように BNLアルゴリズムと BKAJアルゴリズムを使用するかを制御 ※ BNLJ: JOINバッファというメモリ領域を使ってスキャンの回数を減らすアルゴリズムを利用 |
| batched_key_access | off |
Bached Key Access 結合したテーブルと結合バッファーの両方でのインデックスアクセスを提供する、Batched Key Access (BKA) 結合アルゴリズムの使用を制御 ※ BKAJ: MRRとBNLJの組み合わせのアルゴリズムを利用 ※ JOINバッファを利用しつつMRRスキャンで行のID順にfetchをする ※ データ量が巨大でストレージからの読み取りバッファが何度も発生する状況で有効的 |
| materialization | on |
サブクエリー実体化 通常メモリー内に一時テーブルとしてサブクエリー結果を生成することによって、クエリー実行を高速化する ※ ハッシュインデックスを使用してテーブルをインデックス付けし、高速かつ低コストにルックアップできる場合がある |
| subquery_materialization_cost_based | on |
サブクエリー実体化 サブクエリ実体化やIN -> EXISTSサブクエリ変換の選択をコストベースで制御 |
| semijoin | on |
セミジョイン(準結合) WHERE句やON句にINやEXISTSを使用したサブクエリに対して準結合を行うかを制御 |
| loosescan | on |
セミジョイン(準結合) サブクエリ内のテーブルの結合するカラムに対してインデックスが作成されている場合に動作、重複しないようにサブクエリテーブルをスキャン |
| firstmatch | on |
セミジョイン(準結合) 外部表の各行に対して、内部表に一致するものが見つかったら、即座二行を返す、見つかるまで調べて1行だけ返却する準結合 |
| duplicateweedout | on |
セミジョイン(準結合) サブクエリに対して通常の結合を行い、一時テーブルを作成して、その一時テーブル内で重複レコードを除外 |
| use_index_extensions | on |
インデックス拡張 |
| condition_fanout_filter | on |
条件フィルタ 2つ以上のテーブルの結合時に動作する 行の組合せの数が急速に増加しないように、接頭辞数が少ないテーブルから準に結合するように最適化 |
| derived_merge | on |
派生テーブルマージ |
| prefer_ordering_index | on | LIMITクエリの最適化 結果セット全体をフェッチして、余分なデータを破棄するのではなく、クエリーで LIMIT句で実行 |
| hash_join | off |
ハッシュ結合 MySQL 8.0.2以降で、結合条件に適用できるインデックスがないクエリーに対してハッシュ結合が使用できる |
| hash_join_cost_based | on | No Information |
index_merge_*で指定されたパラメータでwhere句のANDやORの最適化が行われます- range(範囲)スキャンでは、複数値比較の等価範囲の最適化というのが行われます
- こちらはINクエリなどでも利用され、対象のカラムがPrimaryKeyやUnique Indexの設定で、一意に特定できる場合は各範囲の行の見積もりは常に1です
- そうでない場合には、インデックスのダイブまたはインデックス統計を利用します
SET optimizer_switch='engine_condition_pushdown=off';を利用することで、NDBを利用している場合に、indexがついていない検索を5-10倍高速化できる可能性があります- くわしくは、プッシュダウンの最適化を参照してください
- BNLJやBKAJのアルゴリズムを利用する際に、join_buffer_sizeの設定をすることで、JOIN Bufferのメモリ領域のチューニングが可能です
- 大きなサイズのレポーティングを出力する前に
SET join_buffer_size=67108864大きなサイズを指定することも可能
condition_fanout_filterの設定で結合が順序が最適化された結果思わぬ順番でテーブルがJOINされてしまうことがあります
- 回避するには、straight join構文を使用する方法があります
- indexの付与が未完全でトラブった事例もあるので気をつけましょう
- Amazon Aurora Ver2(MySQL 5.6 or 5.7) または 3(MySQL8) の大規模結合のベストプラクティスとして詳解をされています
hash_join_cost_basedについては、マニュアルに記載がないのですが、8.0での追加削除パラメータが一覧になっているので、今後の追加に期待をしましょう
3. 検証用のローカルMySQLの設定
SQLの検証ができるようにローカルのmysqlサーバーの設定をします
my.cnf
- 長いSQLがエラーにならないように、事前に
max_allowed_packetを多めに設定しておきます - 正しくtraceができない場合がありエラー判別しづらいので、オプティマイザトレースの有効化と
optimizer_trace_max_mem_sizeも多めに設定しておきます optimizer_search_depthも0に設定して、MySQLのオプティマイザの判断に委ねますquery_cache_typeはdefaultでOFFですが、ローカルのデバック時にはshow variablesでOFFになっていることを確認してください
my.cnfの設定完了後、MySQLを再起動して指定したパラメーターを有効化しましょう
また、検証のために一時的に設定を有効にしたい場合には、現在ログインしているセッションでのみ設定を有効化するために、下記の様なコマンドを利用できます
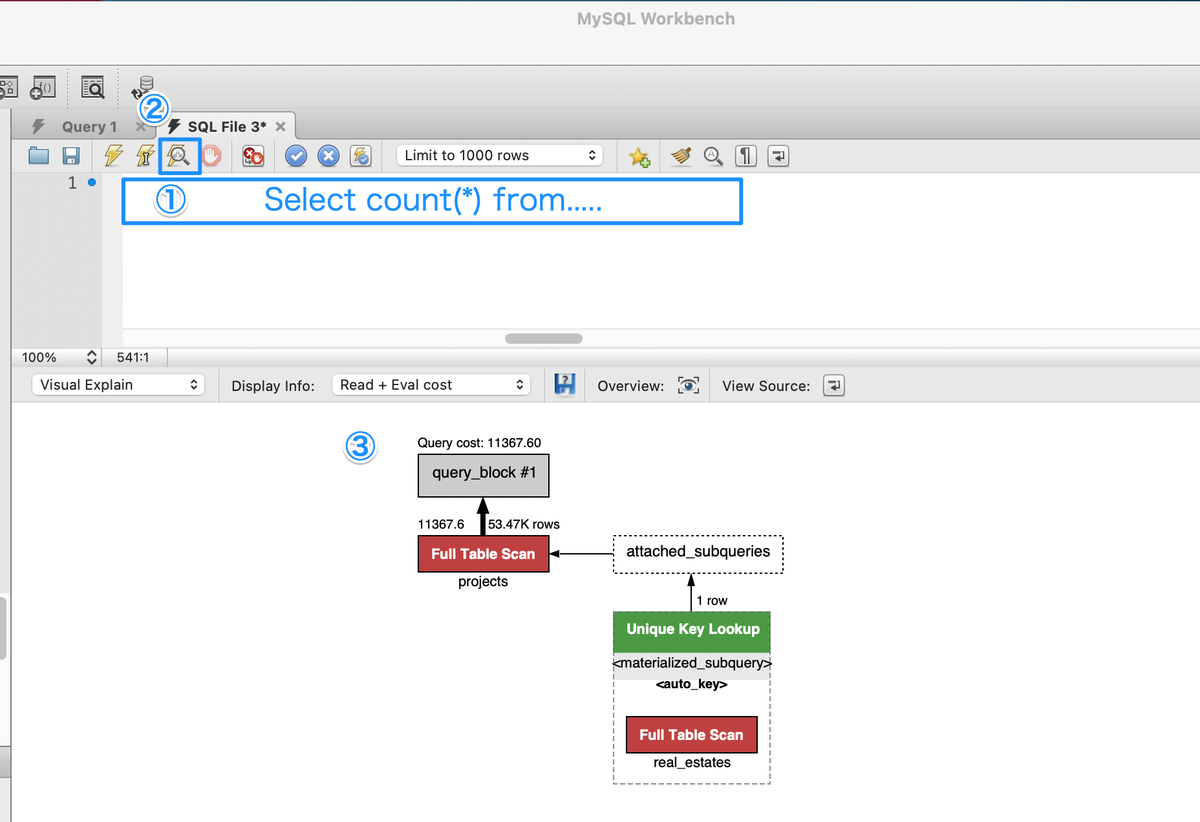
4. Show warningで動いているOptimizerを確認する
![]() Messageの中のクエリを拡大してみる
Messageの中のクエリを拡大してみる

- Optimizerの動作を一目瞭然で確認できます
<exists>はサブクエリー述語は EXISTS 述語に変換されているselect #2N の id 値を持つ行に関連付けられます<in_optimizer >ユーザーにとっては意味がない内部オプティマイザオブジェクト<cache>式 (スカラーサブクエリーなど) が 1 回実行され、あとで使用するために、結果の値がメモリーに保存された状態- その他、サブクエリの実体化を示す、
<materialize>や一時テーブルの自動的に生成されるキーの<auto_key>など様々なオプティマイザが自動的に動いています optimizer_switchで指定できるものとそうでないものがあります- 詳細Explain出力の確認についてを参照してください
5. OPTIMIZER_TRACEを確認する
Optimizer traceをonにした場合に、上記のコメントでexplainクエリを実行後に、直前のオプティマイザの動作が確認できるようになります。
今回は詳細は説明は割愛します。
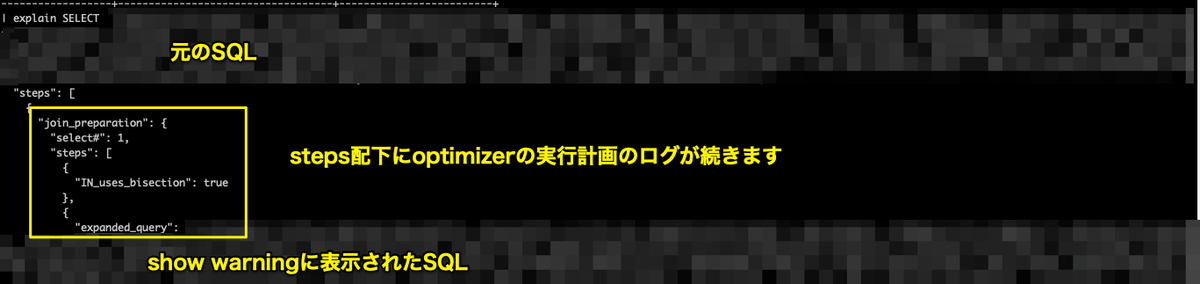
6. MySQL Work BenchのVisual Explainを使う
Downlod MySQL Work Benchをダウンロードしてビジュアライザを利用できるようにします