はじめに
スペースリーでインターンをしている大隣嵩です。
弊社は空間データ活用プラットフォームを提供しており、パノラマ画像を使った空間の3Dビューワーをリリースしました。
研究開発チームでは、更なる精度向上やコンテンツ制作負担軽減のため、より精度が高く柔軟な3D再構成技術の研究開発を進めています。

NeRF(Neural Radiance Fields)[1]では、写実的な陰影表現を含むシーンの高精度な3Dキャプチャを行うことができます。最近になって、NeRFを簡単に試すことができるアプリ(LumaAI[2])やフレームワーク(nerfstudio[3])が登場したことにより、研究者以外の人でも簡単にNeRFを試すことができるようになっています。今回は、屋内シーンの360度動画を使ってNeRF(nerfstudio)の精度検証を行った結果を紹介します。NeRFの概要については単眼からの3D復元を行なったShaRFに関する以前の記事をご参照ください(https://tech.spacely.co.jp/entry/2022/08/18/150000)。
NeRFStudio
NeRFStudio[3]では、簡単にNeRFの学習、推論、可視化を行うための機能が提供されています。また、NeRFの各コンポーネントをモジュール化しており、直感的に追加の実装ができます。
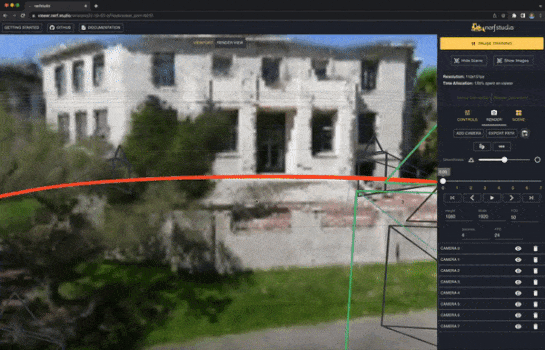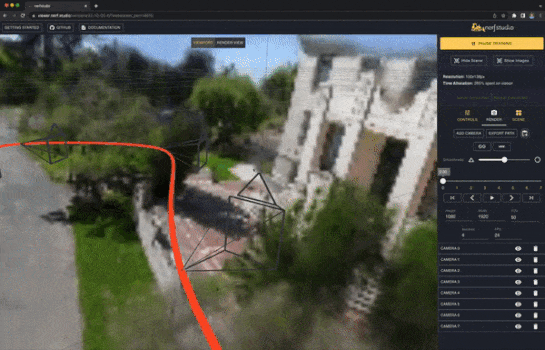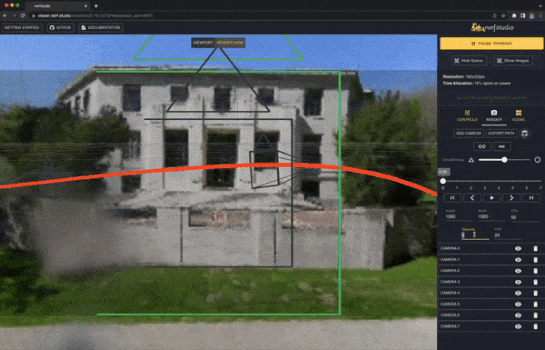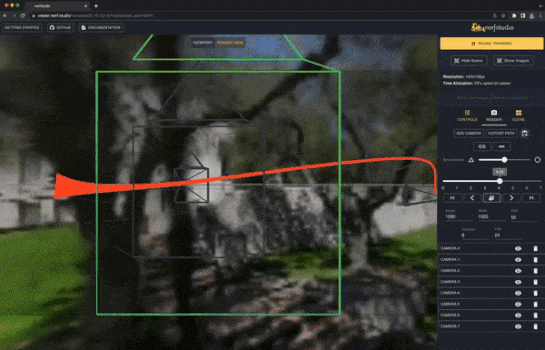
nerfacto
実データの静的なシーンでNeRFを学習させるために、実データに適した複数の公開手法(NeRF--[4]、MipNeRF-360[5]、Instant-NGP[6]、NeRF-W[7])を組み合わせたnerfactoモデルがNeRFStudioでは利用できます。
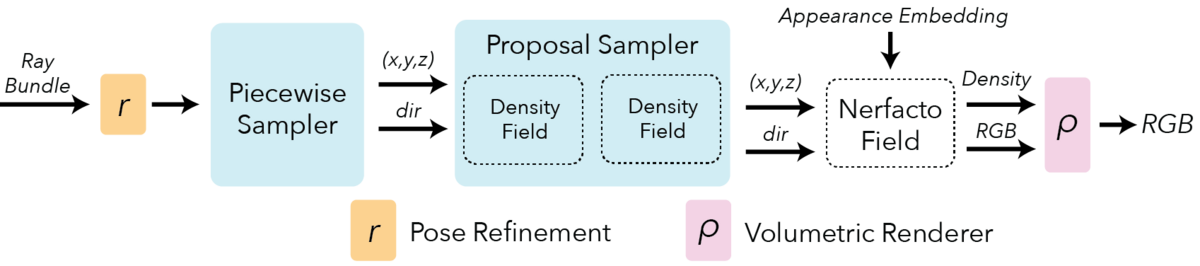
Camera pose refinement
COLMAP[8]などのSfMツールやスマートフォンなどのデバイスから取得したカメラポーズには、しばしば誤差が生じます。カメラポーズのずれにより、各画像間の対応がずれて、NeRFの学習に誤差が蓄積されてしまいます。この問題を解決するために、NeRF--の手法を参考に、カメラポーズの計算箇所に勾配を伝播させ、NeRFと共にカメラポーズの最適化を行います。
Scene contraction(Piecewise Sampler)
オリジナルのNeRFでは、広いシーンで光線のサンプリングが疎になり、復元精度が低下します。この問題を解決するために、MipNeRF-360の手法を参考にPiecewise Samplerを利用します。Piecewise Samplerでは、カメラから距離1までの範囲では一様にサンプリングし、距離1を超えると、サンプリング間隔が徐々に大きくなるようにサンプリングします。これにより、遠くの点をサンプリングしつつ、手前のオブジェクトのサンプリング密度を高めることができます。
Proposal sampling
光線が最初に交差するオブジェクトの表面にサンプリングを集中させるために、MipNeRF-360で提案されたProposal Networkを利用します。Proposal Networkの出力をもとに、光線のサンプリング位置を決定します。
Hash encoding
Instant-NGPで提案されたHash encodingを利用します。Hash encodingにより、MLPのサイズを小さくすることができ、NeRFの学習・推論の速度が劇的に向上します。
Per image appearance conditioning
実データの画像群では、シーンごとの照明条件が異なる場合があります。この照明条件の違いを吸収するために、NeRF-Wで利用されたAppearance Embeddingを追加しています。
LumaAI
Luma AIは、スマートフォンで高精度にオブジェクトや風景の3Dキャプチャができるツールです。NeRFをベースにした技術を用いて、1つのシーンに対して約30分程度の短時間で、自由なカメラワークからシーンをレンダリングする自由視点映像を作成することができます。Luma AIで作成された作品は、公式サイトで閲覧することができます(https://captures.lumalabs.ai/)。
実験
実験データ
360度カメラを使って夜のオフィス(office_night)、昼のオフィス(office_daytime)、廊下(corridor)、トイレ(toilet)の4つのシーンの撮影を行いNeRFの学習のためのデータとしました。各シーンの画像例を図3に示します。








実験条件・手順
実験の流れ
実験で行った処理は以下のようなフローになります。 1. 360度動画からの透視投影画像の切り出し(COLMAPを使えるようにするため) 2. COLMAPによるカメラパラメータ推定 3. NeRFモデルの学習 4. 任意視点でのパノラマ動画の生成
実験条件
360度カメラを使って撮影した30秒~2分の動画の各360度画像から撮影者が映らないように視野角90度で6枚ずつ透視投影画像を切り出し(図4)、COLMAPを使ってカメラパラメータを求めました。 今回の実験では、COLMAPの処理が数日以内で終わるように画像枚数を多くても4000枚程度になるよう、適宜fpsを下げてCOLMAPに入力する画像群を作成しました。






それぞれのCOLMAP前後での画像枚数は表1の通りです。今回の実験では、COLMAPにより8割以上の画像のカメラパラメータを求めることができました。
表1: COLMAP前後での画像枚数の一覧
COLMAP前 |
COLMAP後 (COLMAP前と比較した画像枚数の割合) |
|
|---|---|---|
office(昼) |
4026 |
3982 (98.9%) |
office(夜) |
4044 |
4032 (99.7%) |
corridor |
4122 |
3307 (80.2%) |
toilet |
2946 |
2564 (87.0%) |
モデルはnerfactoをベースにappearance embeddingは使わずに、各イテレーションで4096本の光線を学習に使用し、30,000ステップの学習を行いました。GeForce GTX 1080 1枚で学習を行い、各シーンの学習に約2時間かかりました。NVIDIA A100 GPUを使うと約30分ほどで学習できます。また、推論時の画像合成では960x480の360度画像1枚あたり約15秒かかりました。 また、比較のためにcorridorとtoiletのシーンに対してLumaAIを使ったNeRFの学習・自由視点映像の作成を行いました。LumaAIでは、画像のアップロードから一連の処理が終わるまでに30分ほどを要しました。
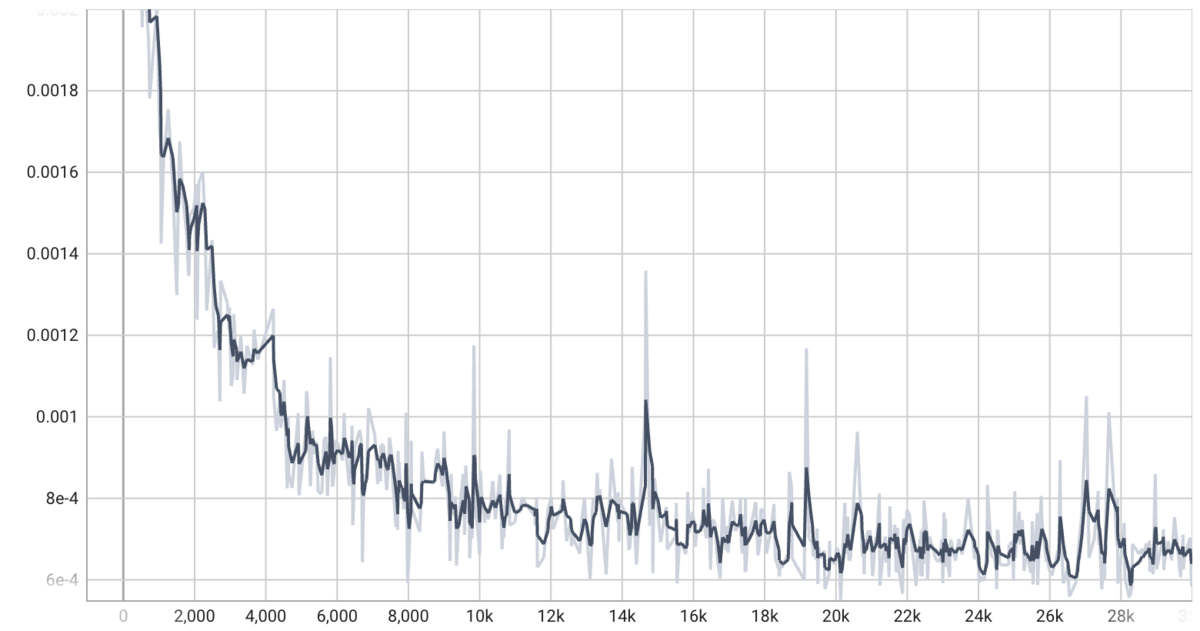
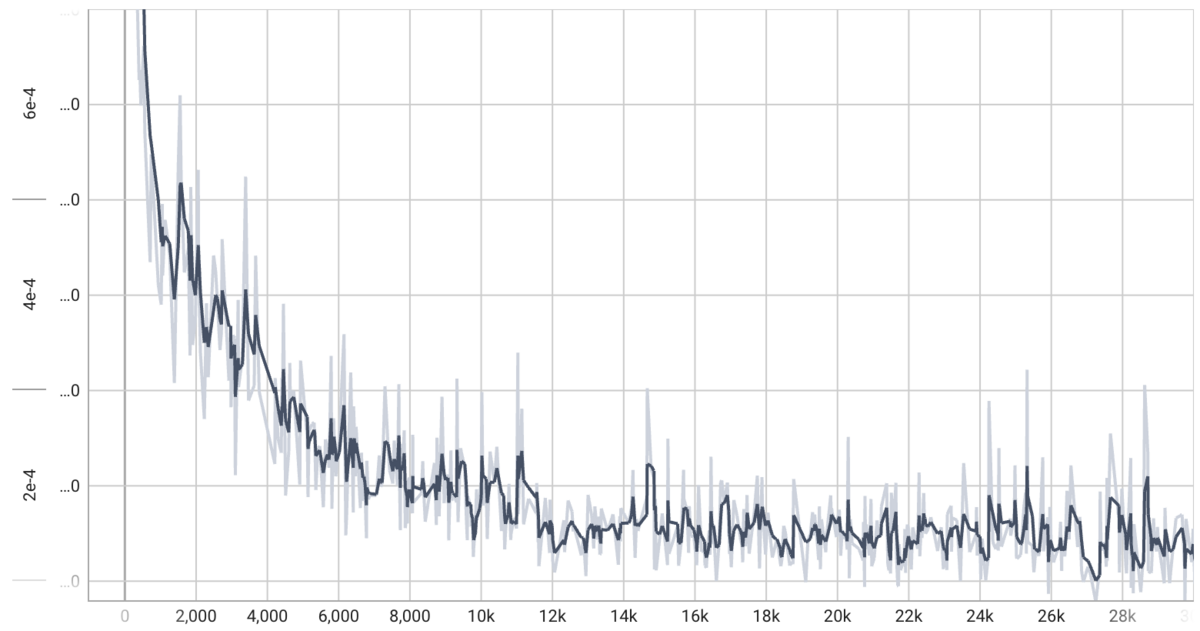
学習の推移
各シーンでnerfactoを学習した時のロスの推移は図5です。いずれのシーンも30,000ステップの学習でロスが十分収束しました。


また、各シーンで学習途中の画像をレンダリングし、学習の推移を可視化しました。それぞれのシーンで視覚的にも学習が収束していることが確認できました。
office_night

office_daytime

corridor

toilet

結果
LumaAIの結果


今回はcorridorとtoiletのみ検証を行いましたが、後述するnerfactoと比較すると、天井付近にアーティファクトが生じる結果となりました。ただ、COLMAPなどのカメラパラメータを求めるための前処理を必要とせず、画像のアップロードから30分で結果が得られるのはとても実用的です。
nerfactoの結果
office_night

office_daytime

corridor

toilet

今回の実験で試したシーンでは、違和感のない自由視点映像が得られました。NeRFでは、シーンごとに学習が必要で、各学習に数十分かかるため、計算コストは重たい一方で、従来技術では考えられないほどの精度で自由視点映像を作成することができます。また、壁などの低テクスチャ領域や、一部のオブジェクトでアーティファクトが発生しましたが、これは撮影の工夫や、深度情報の追加などによって対応できると考えています。
nerfactoによる俯瞰視点の合成結果
nerfactoを使って部屋を天井から見下ろす俯瞰視点からの画像合成を行いました。それぞれのシーンで天井付近を移動する360度動画と中心の前方を見るように切り出した透視投影画像による俯瞰映像をそれぞれ示します。
office_night


office_daytime
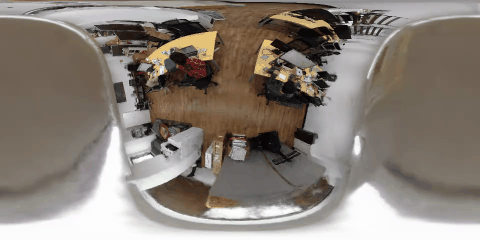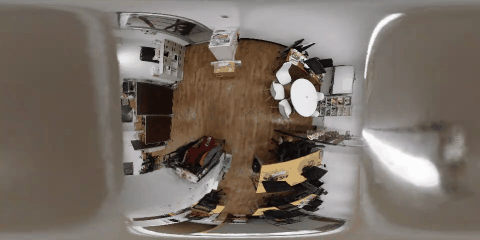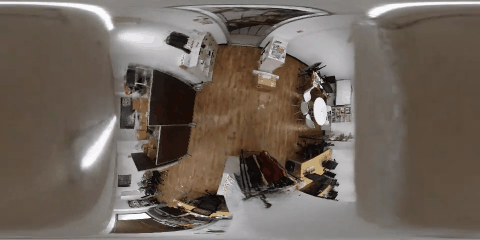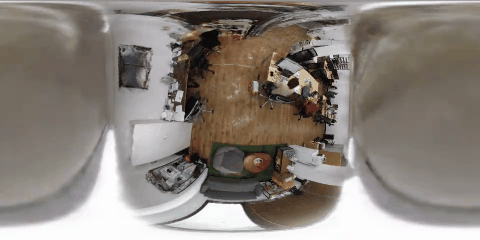

corridor


toilet


天井から床を見下ろす視点は学習データセットに存在しないですが、それでも、十分に学習ができ、精度のよい合成結果が得られることがわかりました。
まとめ
屋内シーンを撮影した360度動画からNeRFを学習した実験を紹介しました。今回の実験では、NeRFを実データに適用するために開発されたモデルであるnerfactoを用いました。360度動画をnerfactoモデルに適用する際には、どの画像形式(パノラマ、fisheye、cubemap)で扱うか、どのようにして透視投影画像を切り出すかなど考慮すべき点がいくつかあります。また、COLMAPやNeRFの計算量を考慮しつつ、シーンの重なりが十分取れる範囲でデータセットを構築することが重要になります。
さいごに
spacelyでは一緒に働いてくださる方を募集中です。
カジュアル面談も実施していますので気になる方は是非ご連絡ください!
参考文献
[1] Ben Mildenhall, Pratul P. Srinivasan, Matthew Tancik, Jonathan T. Barron, Ravi Ramamoorthi and Ren Ng. NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis. In ECCV, 2020.
[2] Luma AI
[3] Matthew Tancik, Ethan Weber, Evonne Ng, Ruilong Li, Brent Yi, Justin Kerr, Terrance Wang, Alexander Kristoffersen, Jake Austin, Kamyar Salahi, Abhik Ahuja, David McAllister and Angjoo Kanazawa. Nerfstudio: A Modular Framework for Neural Radiance Field Development. arXiv:2302.04264, 2023.
[4] Zirui Wang, Shangzhe Wu, Weidi Xie, Min Chen and Victor Adrian Prisacariu. NeRF--: Neural Radiance Fields Without Known Camera Parameters. arXiv:2102.07064, 2021.
[5] Jonathan T. Barron, Ben Mildenhall, Dor Verbin, Pratul P. Srinivasan and Peter Hedman. Mip-NeRF 360: Unbounded Anti-Aliased Neural Radiance Fields. In CVPR, 2022.
[6] Thomas Müller, Alex Evans, Christoph Schied and Alexander Keller. Instant Neural Graphics Primitives with a Multiresolution Hash Encoding. In SIGGRAPH, 2022.
[7] Ricardo Martin-Brualla, Noha Radwan, Mehdi S. M. Sajjadi, Jonathan T. Barron, Alexey Dosovitskiy and Daniel Duckworth. NeRF in the Wild: Neural Radiance Fields for Unconstrained Photo Collections. In CVPR, 2021.
[8] Johannes Lutz Schönberger, Enliang Zheng, Marc Pollefeys and Jan-Michael Frahm. Pixelwise View Selection for Unstructured Multi-View Stereo. In ECCV, 2016.